In practice, there are times when it is valuable to integrate multiple datasets into a single unified dataset, for further analysis.
This allows us to gain deeper insights and a more comprehensive understanding.
For example, a financial analyst may merge transaction-level data with customer demographic information to identify spending patterns, or combine market price data with macroeconomic indicators to better model asset performance.
If you’ve used the VLOOKUP function in spreadsheet software, or the JOIN clause in SQL, you’ve already merged datasets. Let’s explore how to merge datasets in Python.
16.1 Merging DataFrames
We can use the merge function from pandas to join two datasets together. The merge function accepts two DataFrame objects as initial parameters, as well as a how parameter to indicate the join strategy (see “Join Strategies” section below). There are additional parameters to denote which columns or indices to join on.
In this approach, we invoke the merge method on one of the DataFrame objects, and pass the other as a parameter.
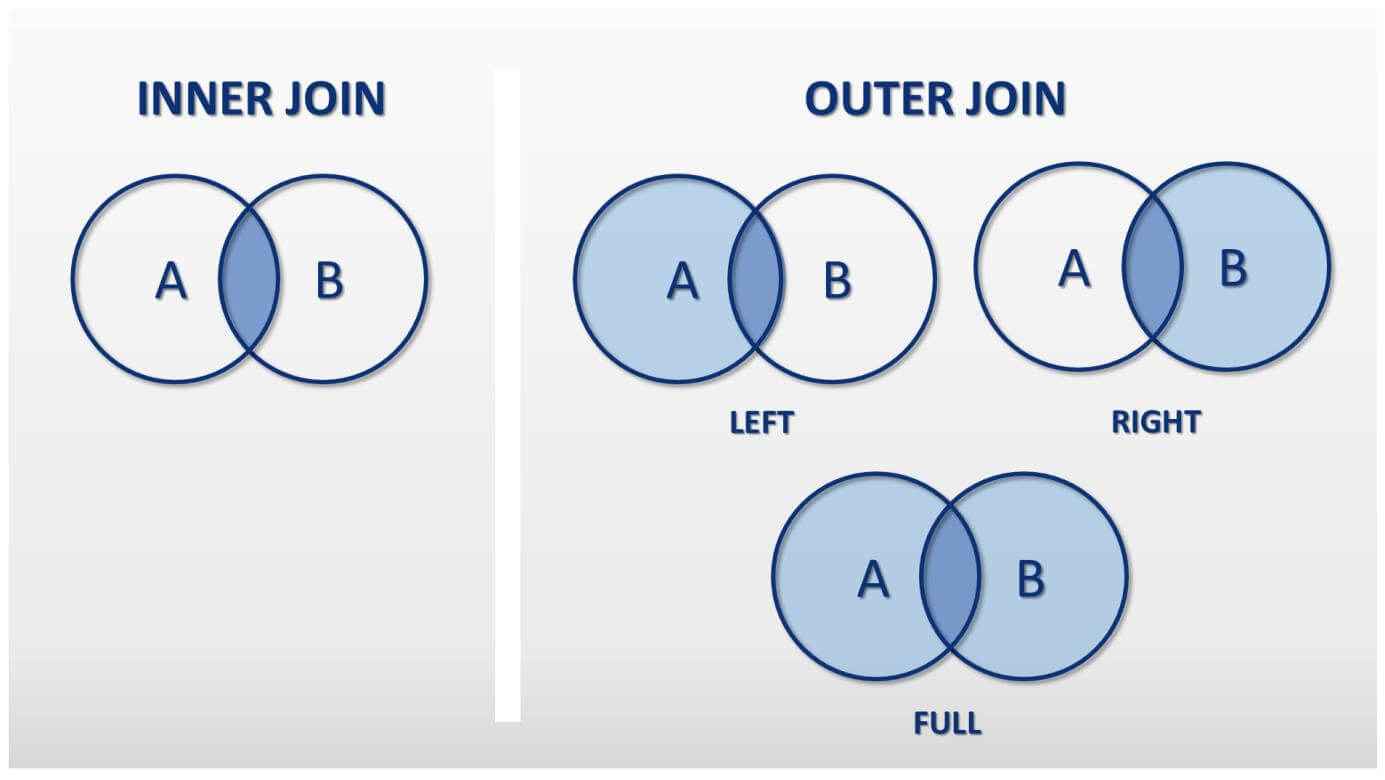
16.2 Join Strategies
When we read the documentation for these merge methods, we see there are many options for the how parameter, including “inner”, left”, “right”, and “outer”.
To know which value to choose in a particular situation, let’s discuss different these join strategies in more detail.
Join Strategies: inner vs outer joins
Inner Join: Keeps only rows where the join value is matching across both datasets.
Left Outer Join: Keeps all rows from the left dataset, and matches data from the right where available.
Right Outer Join: Keeps all rows from the right dataset and matches data from the left where available.
Full Outer Join: Keeps all rows and columns from both datasets. Values will be null if there isn’t a match.
16.3 Example 1: Customers and Transactions
To further illustrate the different join strategies, let’s consider the following two datasets about customers and transactions:
It looks like there is a “one to many” relationship between the customers and their transactions, where a single customer may have multiple transactions.
Both of the datasets share a “CustomerID” column, which seems to be an index reference that uniquely identifies a given customer. There seem to be some values in the “CustomerId” column that are common across both datasets, so it will be possible to join the datasets on this basis.
We see customers #1 and #2 are present in both datasets. However there isn’t a perfect overlap, as customer #5 is not present in the customers dataset, and customers #3 and #4 are not present in the transactions dataset.
Let’s join these same two datasets in a variety of different ways, to illustrate each join strategy.
16.3.1 Inner Join
Performing an inner join:
from pandas import mergemerged_df = merge(customers, transactions, how="inner", on="CustomerID")merged_df
The merged dataset contains the entire left dataset, with additional columns from the right. Merged values from the right will be null in the event there was no match.
The merged dataset contains the entire right dataset, with additional columns from the left. Merged values from the left will be null in the event there was no match.
We see all the rows and columns from both datasets. The values from the left and right are null if there wasn’t a match.
16.4 Example 2: Treasury Yield Curves
Let’s practice merging different datasets together, in order to perform some real world financial analysis. e will merge the data to explore insights about inverted yield curves.
In this example, we’ll use two different datasets of treasury yields from the AlphaVantage API: one with a short-term (three month) maturity, and the other with a long-term (ten year) maturity.
TipData Source
These datasets use the Treasury Yield endpoint from the AlphaVantage API. This endpoint returns the daily, weekly, or monthly US treasury yield for a given maturity timeline (3-month, 10-year, 30-year, etc.).
Source: Board of Governors of the Federal Reserve System (US), Market Yield on U.S. Treasury Securities at 3-month, 2-year, 5-year, 7-year, 10-year, and 30-year Constant Maturities, Quoted on an Investment Basis, retrieved from FRED, Federal Reserve Bank of St. Louis.
16.4.1 Dataset A: Long-term Maturity
Fetching a dataset of long-term treasury yields maturing in ten years:
In this case we specify we want to join on the index from both datasets. Here we are using an “inner” join strategy, to keep only the rows that have matching timestamp values across both datasets.
print("TIME RANGE (MERGED DATASET):")print(merged_df.index.min())print(merged_df.index.max())
TIME RANGE (MERGED DATASET):
1981-09-01
2024-11-01
Notice, the resulting merged dataset starts in 1981, because we used an “inner” join, and because that is the earliest month shared across ALL source datasets (as constrained by the 3-mo maturity dataset).
16.6 Analyzing Merged Data
The reason why we went through the trouble of merging the data is so we can compare the two datasets more easily, for example to identify which periods had an “inverted yield curve” where the short-term yield was greater than the long-term yield.
We can identify periods of inversion visually by plotting both datasets on the same graph: