The pandas package provides a super-charged datatype called the DataFrame, which represents tabular, spreadsheet-style data with rows and columns.
We can obtain a DataFrame object by either reading a CSV file, or by constructing one ourselves.
1.1 Reading CSV Files
If we have data files in tabular format (for example in CSV format, or XLS / XLSX format), we can use the read_csv function, or read_excel function, respectively, to convert that data into a DataFrame object. Here we will focus primarily on CSV files.
We can use these functions to read files saved locally, as well as hosted on the Internet.
1.1.1 Local Files
In terms of reading local files, the file needs to be in the same location as the Python code.
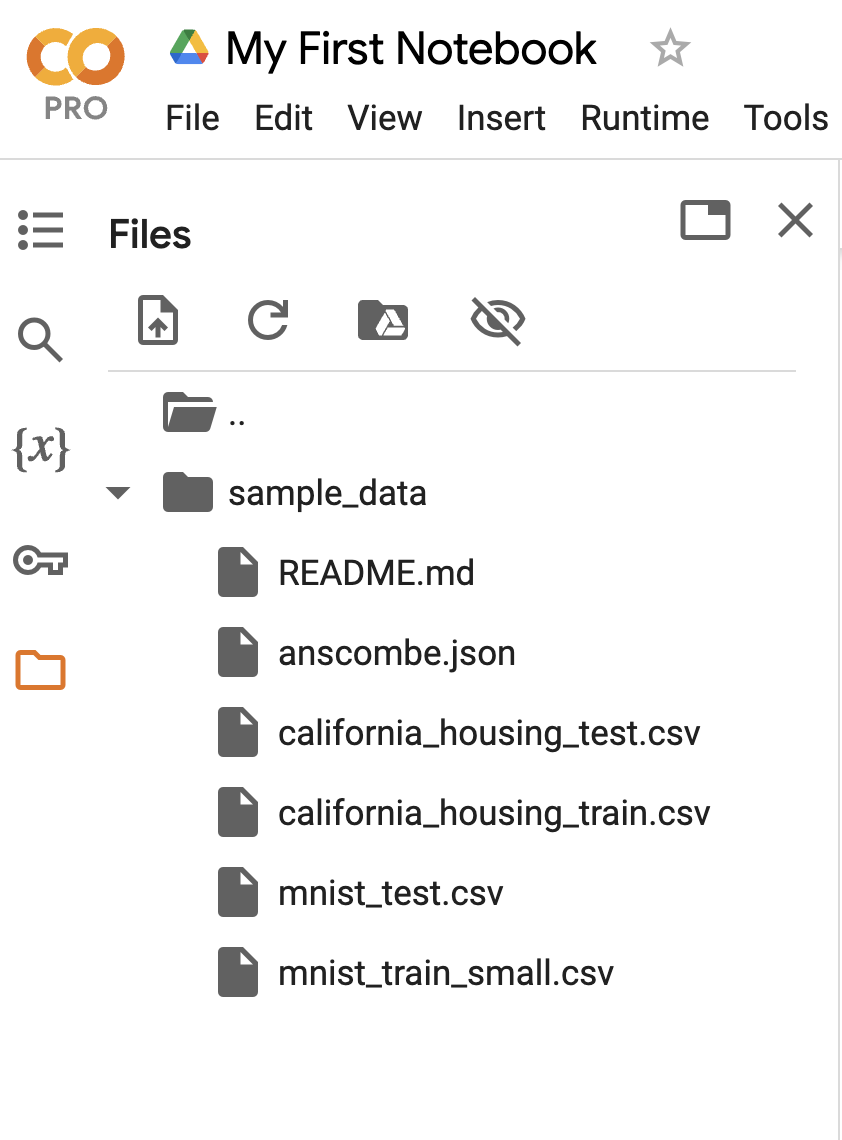
For example, in the Colab Filesystem, there is a CSV file called “california_housing_train.csv” in the “sample_data” directory:
Example CSV file in the Colab Filesystem
To read this file, we pass the relative filepath as a parameter to the read_csv function:
from pandas import read_csvcsv_filepath ="sample_data/california_housing_train.csv"df = read_csv(csv_filepath)print(type(df))df.head()
<class 'pandas.core.frame.DataFrame'>
longitude
latitude
housing_median_age
total_rooms
total_bedrooms
population
households
median_income
median_house_value
0
-114.31
34.19
15.0
5612.0
1283.0
1015.0
472.0
1.4936
66900.0
1
-114.47
34.40
19.0
7650.0
1901.0
1129.0
463.0
1.8200
80100.0
2
-114.56
33.69
17.0
720.0
174.0
333.0
117.0
1.6509
85700.0
3
-114.57
33.64
14.0
1501.0
337.0
515.0
226.0
3.1917
73400.0
4
-114.57
33.57
20.0
1454.0
326.0
624.0
262.0
1.9250
65500.0
1.1.2 Hosted Files
In terms of CSV formatted data hosted on the Internet, we note the URL of the hosted file, and pass it to the read_csv function:
from pandas import read_csvrequest_url ="https://raw.githubusercontent.com/prof-rossetti/intro-to-python/main/data/daily_adjusted_nflx.csv"df = read_csv(request_url)print(type(df))df.head()
<class 'pandas.core.frame.DataFrame'>
timestamp
open
high
low
close
adjusted_close
volume
dividend_amount
split_coefficient
0
2021-10-18
632.1000
638.4100
620.5901
637.97
637.97
4669071
0.0
1.0
1
2021-10-15
638.0000
639.4200
625.1600
628.29
628.29
4116874
0.0
1.0
2
2021-10-14
632.2300
636.8800
626.7900
633.80
633.80
2672535
0.0
1.0
3
2021-10-13
632.1791
632.1791
622.1000
629.76
629.76
2424638
0.0
1.0
4
2021-10-12
633.0200
637.6550
621.9900
624.94
624.94
3227349
0.0
1.0
1.2 Constructing DataFrames
We can also construct our own DataFrame objects.
If we have Python data in an eligible format (list of lists, list of dictionaries, dictionary of lists), we can pass that data to the DataFrame class constructor to obtain a DataFrame object back.
1.2.1 List of Lists
Here, we are constructing a DataFrame from a list of lists:
from pandas import DataFrame# list of lists:prices = [ ["2020-10-01", 100.00], ["2020-10-02", 101.01], ["2020-10-03", 120.20], ["2020-10-04", 107.07], ["2020-10-05", 142.42], ["2020-10-06", 135.35], ["2020-10-07", 160.60], ["2020-10-08", 162.62],]df = DataFrame(prices, columns=["date", "stock_price_usd"])print(type(df))df.head()
<class 'pandas.core.frame.DataFrame'>
date
stock_price_usd
0
2020-10-01
100.00
1
2020-10-02
101.01
2
2020-10-03
120.20
3
2020-10-04
107.07
4
2020-10-05
142.42
In this case we wind up with a row for each item in the outer list, and a column for each value in the inner list.
Because the lists don’t have column names, we supply those separately, using the columns parameter.
1.2.2 List of Dictionaries
Here, we are constructing a DataFrame from a list of dictionaries (i.e. “records” format), which is a very common and usable format: