5 Regression
Regression is a supervised learning task where the variable we are trying to predict is continuous.
Some examples of continuous data include:
- House Prices (in dollars)
- Life Expectancy (in years)
- Employee Salary (in dollars)
- Distance to the Nearest Galaxy (in light years)
In finance, regression can help predict stock prices, assess risk, forecast revenue, or understand how economic variables affect one another. For example, we might use regression to predict future stock returns based on historical data of interest rates, company earnings, or macroeconomic indicators.
In this chapter, we will explore different regression models, and introduce key performance metrics used to evaluate the effectiveness of regression models.
5.1 Regression Objectives
Regression analysis is used to model the relationship between a dependent variable (i.e. the target) and one or more independent variables (i.e. the predictors or features). The goal of regression is to find an equation that best describes this relationship and enables the prediction of future outcomes based on new inputs.
The overall general equation for a regression is:
\[ y = f(X) + \epsilon \]
Where:
- \(y\) is the dependent variable, or target
- \(X\) represents the independent variable(s), or features
- \(f(X)\) is the function describing the relationship between \(X\) and \(y\) (this can be linear or non-linear)
- \(\epsilon\) is the error term, or residuals, representing the difference between predicted and actual values
5.2 Regression Models
There are a few different types of regression models, each of which performs calculations in a slightly different way. In this section, we will discuss three popular regression models: linear regression, lasso regression, and ridge regression. Linear regression is the most basic form of regression model, while the others introduce a process called “regularization” which helps prevent overfitting, and improves the model’s generalizability.
5.2.1 Linear Regression
Ordinary least squares linear regression is the simplest form of regression, assuming a straight-line relationship between the dependent and independent variables. The goal is to minimize the difference between the actual and predicted values.
When there is only one feature, the equation for a linear regression is as follows: \[ y = \beta_0 + \beta_1 X + \epsilon \]
Where:
- \(\beta_0\) is the intercept (the value of \(y\) when \(X=0\))
- \(\beta_1\) is the coefficient representing the slope of the line, which measures how much \(y\) changes for a one-unit change in \(X\)
When there are multiple features, each feature and its corresponding coefficient is included in the regression equation:
\[ y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_n X_n + \epsilon \]
5.2.2 Lasso Regression
Lasso regression is a form of linear regression that includes an additional penalty term to control the magnitude of the coefficients. The Lasso method applies an L1 regularization process, which penalizes the absolute sum of the coefficients. This leads to feature selection, as some coefficients are reduced to zero, effectively excluding irrelevant features from the model.
5.2.3 Ridge Regression
Ridge regression is similar to Lasso regression, but it applies an L2 regularization process, which penalizes the square of the coefficients. Instead of shrinking coefficients to zero like Lasso, Ridge regression forces coefficients to be small, but not zero. This method is useful when multicollinearity is present in the data.
5.3 Regression Models in Python
In Python, we can utilize popular packages to provide access to the various regression models:
- Linear Regression (ordinary least squares):
LinearRegressionclass fromsklearnOLSclass fromstatsmodels
- Ridge Regression:
Ridgeclass fromsklearn
- Lasso Regression
Lassoclass fromsklearn
In future chapters, we will provide more details and examples of how to train these regression models, focusing primarily on linear regression.
5.4 Regression Metrics
Once we have trained a regression model, we need a way of evaluating its performance. This is the role of regression metrics.
Common regression metrics include:
- R-Squared Score
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
- Root Mean Square Error (RMSE)
Each of these metrics provides a measure of how well a regression model explains the observed data. They are concerned with various ways of measuring the total error, or difference between actual and predicted values.
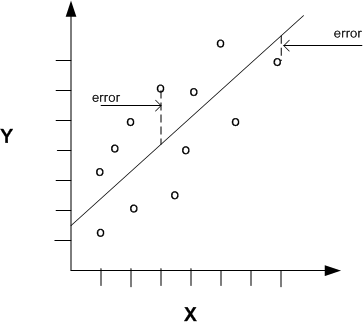
NOTE: except for the R-squared score, where the goal is to achieve values as close to 1 as possible, the objective with the other metrics is to minimize their values.
5.4.1 R-Squared Score
The r-squared score, otherwise known as the “coefficient of determination”, measures the proportion of variance in the dependent variable that is explained by the independent variables.
The equation for r-squared score is as follows:
\[ R^2 = 1 - \frac{SSE}{SST} \]
Where:
- \(SSE\) = Sum of Squared Errors = \(\sum_{i=1}^{n}(y_i - \hat{y_i})^2\)
- \(SST\) = Total Sum of Squares = \(\sum_{i=1}^{n}(y_i - \bar{y})^2\)
Here is an example calculation of r-squared score in Python:
sse = (test_set["Error"] ** 2).sum()
sst = ((test_set["Actual"] - test_set["Actual"].mean()) ** 2).sum()
my_r2 = 1 - (sse / sst)
print("MY R2:", my_r2)The r-squared score is usually expressed on a scale from 0 to 1, where higher positive numbers approaching 1 indicate success:
- A score of 1 indicates the model perfectly fits the data.
- A score of 0 indicates the model explains none of the variability in the data.
- It is also possible for values to be negative, indicating the model performs worse than simply using the mean value of the target variable as the predicted value.
5.4.2 Mean Absolute Error
The mean absolute error (MAE) measures the average magnitude of the errors in a set of predictions, without considering their direction (positive or negative). In other words, MAE is the average absolute difference between actual and predicted values.
The equation for MAE is as follows:
\[ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y_i}| \]
Here is an example calculation of MAE in Python:
my_mae = test_set["Error"].abs().mean()
print("MY MAE:", my_mae)MAE is expressed in the same units as the target variable, making it interpretable and useful for understanding the scale of the errors.
5.4.3 Mean Squared Error
The mean squared error (MSE) calculates the average of the squared differences between actual and predicted values. It penalizes larger errors more than MAE due to the squaring of the differences.
The equation for MSE is as follows: \[ MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y_i})^2 \]
Here is an example calculation of MSE in Python:
my_mse = (test_set["Error"] ** 2).mean()
print("MY MSE:", my_mse)MSE is expressed in squared terms, so we would need to take the square root to interpret the error in the same units as the target.
5.4.4 Root Mean Squared Error
RMSE is simply the square root of the MSE.
The equation for RMSE: \[ RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y_i})^2} \]
my_rmse = my_mse ** 0.5
print("MY RMSE:", my_rmse)Like the MAE, RMSE provides an interpretable error metric in the same units as the target variable, making it useful for understanding the scale of the errors. However due to differences in their calculation formula, the values for the MAE and RMSE will often differ. They each provide a different way of measuring the total error.
5.5 Regression Metrics in Python
In Python, it is possible to calculate these regression metrics ourselves, based on the actual and predicted values.
However, for convenience, we will generally prefer to use corresponding regression metric functions from the sklearn.metrics submodule:
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
r2 = r2_score(y_true, y_pred)
print("R2:", r2)
mae = mean_absolute_error(y_true, y_pred)
print("MAE:", mae)
mse = mean_squared_error(y_true, y_pred)
print("MSE:", mse)
rmse = mse ** 0.5
print("RMSE:", rmse)When using these functions, we pass in the actual values (y_true), as well as the predicted values (y_pred), We take these values from the training set to arrive at training metrics, or from the test set to arrive at test metrics.