from google.colab import userdata
API_KEY = userdata.get("ALPHAVANTAGE_API_KEY")Joining and Merging
In real world data analyses, it may be valuable to integrate multiple datasets, to gain insights.
Let’s practice merging different datasets together.
In this example, we’ll use a number of different economic and market indicator datasets from the AlphaVantage API.
After fetching the raw data, we’ll prepare each source dataset in such a way that allows it to be merged with the others later. In order for the datasets to be merged, they need some common column of values. Think of a VLOOKUP function in spreadsheet software, or a JOIN clause in an SQL query. We will be performing a similar operation here.
After we fetch the data, you’ll see of these datasets has a timestamp column, which represents the values using a monthly frequency.
Because we’ll have a timestamp column in each of the datasets, and because the values of this timestamp column will be expressed in the same way (i.e. at the beginning of each month), this allows us to use these common values to merge the datasets.
Fetching Data
We have obtained an AlphaVantage API Key and set it as a notebook secret.
Inflation
https://www.alphavantage.co/documentation/#inflation
from pandas import read_csv
request_url = f"https://www.alphavantage.co/query?function=INFLATION&apikey={API_KEY}&datatype=csv"
inflation = read_csv(request_url)
inflation.head()| timestamp | value | |
|---|---|---|
| 0 | 2022-01-01 | 8.002800 |
| 1 | 2021-01-01 | 4.697859 |
| 2 | 2020-01-01 | 1.233584 |
| 3 | 2019-01-01 | 1.812210 |
| 4 | 2018-01-01 | 2.442583 |
Here we have annual data. Doesn’t look like the endpoint provides more frequent intervals. So let’s not use this.
Consumer Price Index (CPI)
https://www.alphavantage.co/documentation/#cpi
CPI is widely regarded as the barometer of inflation levels in the broader economy.
The CPI endpoint does provide access to monthly data. So let’s use CPI as our desired measure of inflation.
from pandas import read_csv
request_url = f"https://www.alphavantage.co/query?function=CPI&interval=monthly&apikey={API_KEY}&datatype=csv"
cpi_df = read_csv(request_url)
cpi_df.rename(columns={"value": "cpi"}, inplace=True)
cpi_df.head()| timestamp | cpi | |
|---|---|---|
| 0 | 2024-05-01 | 314.069 |
| 1 | 2024-04-01 | 313.548 |
| 2 | 2024-03-01 | 312.332 |
| 3 | 2024-02-01 | 310.326 |
| 4 | 2024-01-01 | 308.417 |
print("EARLIEST:", cpi_df.iloc[-1]["timestamp"])EARLIEST: 1913-01-01import plotly.express as px
fig = px.line(cpi_df, x="timestamp", y="cpi", title="Consumer Price Index (CPI) by Month", height=350)
fig.show()Federal Funds Rate
https://www.alphavantage.co/documentation/#interest-rate
request_url = f"https://www.alphavantage.co/query?function=FEDERAL_FUNDS_RATE&interval=monthly&apikey={API_KEY}&datatype=csv"
fed_funds_df = read_csv(request_url)
fed_funds_df.rename(columns={"value": "fed"}, inplace=True)
fed_funds_df.head()| timestamp | fed | |
|---|---|---|
| 0 | 2024-05-01 | 5.33 |
| 1 | 2024-04-01 | 5.33 |
| 2 | 2024-03-01 | 5.33 |
| 3 | 2024-02-01 | 5.33 |
| 4 | 2024-01-01 | 5.33 |
print("EARLIEST:", fed_funds_df["timestamp"].min())EARLIEST: 1954-07-01import plotly.express as px
px.line(fed_funds_df, x="timestamp", y="fed", title="Federal Funds Rate by Month", height=350)px.histogram(fed_funds_df, x="fed", #nbins=12,
title="Distribution of Federal Funds Rate (Monthly)", height=350)The Market (S&P 500)
https://www.investopedia.com/articles/investing/122215/spy-spdr-sp-500-trust-etf.asp
The SPDR S&P 500 ETF Trust is one of the most popular funds. It aims to track the Standard & Poor’s (S&P) 500 Index, which comprises 500 large-cap U.S. stocks. These stocks are selected by a committee based on market size, liquidity, and industry. The S&P 500 serves as one of the main benchmarks of the U.S. equity market and indicates the financial health and stability of the economy
https://www.alphavantage.co/documentation/#monthlyadj
We can use the “SPY” ETF as a measure of the market. Looks like the data only covers the past 20 years (see endpoint docs).
from pandas import read_csv
request_url = f"https://www.alphavantage.co/query?function=TIME_SERIES_MONTHLY_ADJUSTED&symbol=SPY&apikey={API_KEY}&datatype=csv"
spy_df = read_csv(request_url)
spy_df.drop(columns=["open", "high", "low", "close", "volume", "dividend amount"], inplace=True)
spy_df.rename(columns={"adjusted close": "spy"}, inplace=True)
spy_df.head()| timestamp | spy | |
|---|---|---|
| 0 | 2024-06-27 | 546.3700 |
| 1 | 2024-05-31 | 525.6718 |
| 2 | 2024-04-30 | 500.3636 |
| 3 | 2024-03-28 | 521.3857 |
| 4 | 2024-02-29 | 504.8645 |
print("ROWS:", len(spy_df))
print("EARLIEST:", spy_df["timestamp"].min())ROWS: 295
EARLIEST: 1999-12-31# standardizing the timestamp values so we can merge on them later
# we have to decide to treat "2023-05-31" as "2023-05" or "2023-06"
# since we see the latest value represents the current incompleted month,
# let's "round down" the monthly values
from pandas import to_datetime
spy_df["timestamp"] = to_datetime(spy_df["timestamp"]).dt.strftime("%Y-%m-01")
spy_df.head()| timestamp | spy | |
|---|---|---|
| 0 | 2024-06-01 | 546.3700 |
| 1 | 2024-05-01 | 525.6718 |
| 2 | 2024-04-01 | 500.3636 |
| 3 | 2024-03-01 | 521.3857 |
| 4 | 2024-02-01 | 504.8645 |
from pandas import to_datetime
# packaging up this code into a reusable function becuse we'll have to perform this same operation on multiple datasets (see cells below related to gold and bitcoin)
def round_down_monthly_timestamp(original_df):
""" Param original_df: pandas DataFrame that has a "timestamp" column of values representing each month"""
# standardizing the timestamp values so we can merge on them later
# we have to decide to treat "2023-05-31" as "2023-05-01" or "2023-06-01"
# since we see the latest value represents the current incompleted month,
# let's "round down" the monthly values
# see: https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior
original_df["timestamp"] = to_datetime(original_df["timestamp"]).dt.strftime("%Y-%m-01")
round_down_monthly_timestamp(spy_df)
spy_df.head()| timestamp | spy | |
|---|---|---|
| 0 | 2024-06-01 | 546.3700 |
| 1 | 2024-05-01 | 525.6718 |
| 2 | 2024-04-01 | 500.3636 |
| 3 | 2024-03-01 | 521.3857 |
| 4 | 2024-02-01 | 504.8645 |
import plotly.express as px
px.line(spy_df, x="timestamp", y="spy", title="S&P 500 (SPY ETF) Prices by Month", height=350)Gold
https://www.investopedia.com/articles/investing/122515/gld-ishares-gold-trust-etf.asp
The SPDR Gold Shares ETF (GLD) tracks the price of gold bullion in the over-the-counter (OTC) market.
https://money.usnews.com/investing/funds/slideshows/best-gold-etfs-to-hedge-volatility
The largest gold exchange-traded fund, or ETF, by a wide margin is the SPDR Gold Trust… And as the fund is benchmarked to physical gold, you can get a direct play on gold bullion prices via this ETF.
OK we can perhaps use the “GLD” index fund as a measure of gold prices.
from pandas import read_csv
request_url = f"https://www.alphavantage.co/query?function=TIME_SERIES_MONTHLY_ADJUSTED&symbol=GLD&apikey={API_KEY}&datatype=csv"
gld_df = read_csv(request_url)
gld_df.drop(columns=["open", "high", "low", "close", "volume", "dividend amount"], inplace=True)
gld_df.rename(columns={"adjusted close": "gld"}, inplace=True)
gld_df.head()| timestamp | gld | |
|---|---|---|
| 0 | 2024-06-27 | 214.99 |
| 1 | 2024-05-31 | 215.30 |
| 2 | 2024-04-30 | 211.87 |
| 3 | 2024-03-28 | 205.72 |
| 4 | 2024-02-29 | 189.31 |
print("ROWS:", len(gld_df))
print("EARLIEST:", gld_df["timestamp"].min())ROWS: 235
EARLIEST: 2004-12-31round_down_monthly_timestamp(gld_df)
gld_df.head()| timestamp | gld | |
|---|---|---|
| 0 | 2024-06-01 | 214.99 |
| 1 | 2024-05-01 | 215.30 |
| 2 | 2024-04-01 | 211.87 |
| 3 | 2024-03-01 | 205.72 |
| 4 | 2024-02-01 | 189.31 |
import plotly.express as px
px.line(gld_df, x="timestamp", y="gld", title="Gold (GLD ETF) Prices by Month", height=350)Bitcoin
https://www.alphavantage.co/documentation/#currency-monthly
The earliest Bitcoin data we have is from 2020.
request_url = f"https://www.alphavantage.co/query?function=DIGITAL_CURRENCY_MONTHLY&symbol=BTC&market=USD&apikey={API_KEY}&datatype=csv"
btc_df = read_csv(request_url)
btc_df = btc_df[["timestamp", "close"]]
btc_df.rename(columns={"close": "btc"}, inplace=True)
print(len(btc_df))
btc_df.head()9| timestamp | btc | |
|---|---|---|
| 0 | 2024-06-28 | 61499.77 |
| 1 | 2024-05-31 | 67472.41 |
| 2 | 2024-04-30 | 60622.10 |
| 3 | 2024-03-31 | 71291.28 |
| 4 | 2024-02-29 | 61179.03 |
print("ROWS:", len(btc_df))
print("EARLIEST:", btc_df["timestamp"].min())ROWS: 9
EARLIEST: 2023-10-31round_down_monthly_timestamp(btc_df)
btc_df.head()| timestamp | btc | |
|---|---|---|
| 0 | 2024-06-01 | 61499.77 |
| 1 | 2024-05-01 | 67472.41 |
| 2 | 2024-04-01 | 60622.10 |
| 3 | 2024-03-01 | 71291.28 |
| 4 | 2024-02-01 | 61179.03 |
import plotly.express as px
px.line(btc_df, x="timestamp", y="btc", title="Bitcoin Prices by Month, in USD", height=350)Merging Data
Let’s merge all datasets together, on the basis of their common date values (i.e. the “timestamp” column common across all datasets).
We use a precise merge on matching timestamp values, instead of making assumptions about the row frequency and order of source datasets. In this way, the merge operation is similar to a VLOOKUP operation in spreadsheet software.
You’ll notice we have been renaming the columns in the source datasets, and ensuring their “timestamp” values are represented in a standardized way (i.e. all at the beginning of month), to facilitate a clean merge on these common values.
print(cpi_df.columns.tolist())
print(fed_funds_df.columns.tolist())
print(spy_df.columns.tolist())
print(gld_df.columns.tolist())
#print(btc_df.columns.tolist())['timestamp', 'cpi']
['timestamp', 'fed']
['timestamp', 'spy']
['timestamp', 'gld']cpi_df.head()| timestamp | cpi | |
|---|---|---|
| 0 | 2024-05-01 | 314.069 |
| 1 | 2024-04-01 | 313.548 |
| 2 | 2024-03-01 | 312.332 |
| 3 | 2024-02-01 | 310.326 |
| 4 | 2024-01-01 | 308.417 |
fed_funds_df.head()| timestamp | fed | |
|---|---|---|
| 0 | 2024-05-01 | 5.33 |
| 1 | 2024-04-01 | 5.33 |
| 2 | 2024-03-01 | 5.33 |
| 3 | 2024-02-01 | 5.33 |
| 4 | 2024-01-01 | 5.33 |
spy_df.head()| timestamp | spy | |
|---|---|---|
| 0 | 2024-06-01 | 546.3700 |
| 1 | 2024-05-01 | 525.6718 |
| 2 | 2024-04-01 | 500.3636 |
| 3 | 2024-03-01 | 521.3857 |
| 4 | 2024-02-01 | 504.8645 |
gld_df.head()| timestamp | gld | |
|---|---|---|
| 0 | 2024-06-01 | 214.99 |
| 1 | 2024-05-01 | 215.30 |
| 2 | 2024-04-01 | 211.87 |
| 3 | 2024-03-01 | 205.72 |
| 4 | 2024-02-01 | 189.31 |
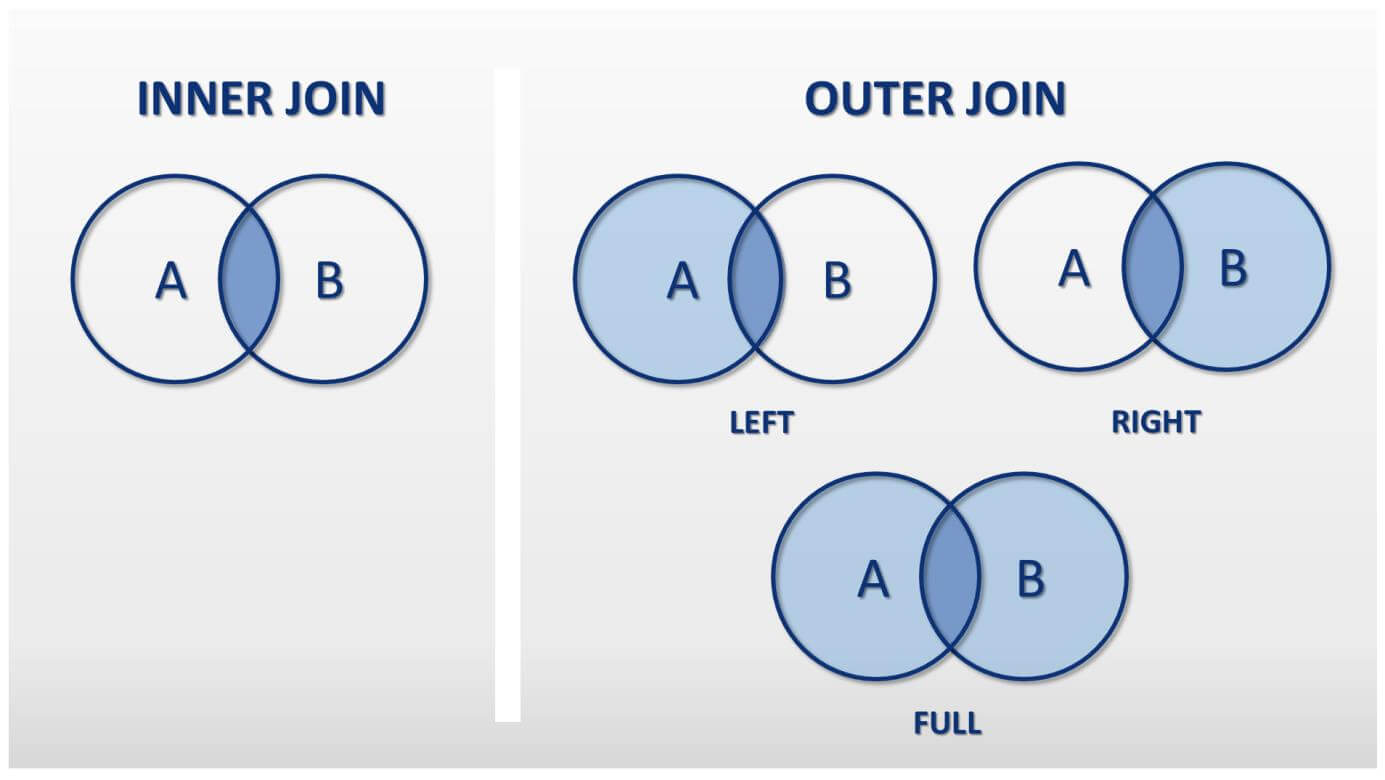
In order to merge the datasets, we’ll use the merge method.
We start by referencing one of the dataframes we want to merge, and then invoke the merge method on it. We pass as a parameter to the merge method another dataframe we want to merge, and also specify the join strategy. In this case we specify which column to join on, and how to join.
Here we are using an “inner” join strategy, to keep only the rows that have matching timestamp values across all datasets.
We can merge any number of additional dataframes in the same way, until we arrive at the final merged dataset.
df = cpi_df.merge(fed_funds_df, on="timestamp", how="inner")
df = df.merge(spy_df, on="timestamp", how="inner")
df = df.merge(gld_df, on="timestamp", how="inner")
#df = df.merge(btc_df, on="timestamp", how="inner")
df.index = df["timestamp"]
df.tail()| timestamp | cpi | fed | spy | gld | |
|---|---|---|---|---|---|
| timestamp | |||||
| 2005-04-01 | 2005-04-01 | 194.6 | 2.79 | 80.2135 | 43.35 |
| 2005-03-01 | 2005-03-01 | 193.3 | 2.63 | 81.7450 | 42.82 |
| 2005-02-01 | 2005-02-01 | 191.8 | 2.50 | 83.2672 | 43.52 |
| 2005-01-01 | 2005-01-01 | 190.7 | 2.28 | 81.5622 | 42.22 |
| 2004-12-01 | 2004-12-01 | 190.3 | 2.16 | 83.4328 | 43.80 |
Notice, the resulting merged dataset starts in 2020, because that is the earliest data available across ALL datasets (as constrained by the Bitcoin dataset). For analyses that only involve two of these indicators, it may be worth it to create a separate merged dataset from only those two (not including Bitcoin), to obtain as much historical context as possible.
len(df)234Now that we have a single merged dataset, let’s save it for later, so we can use it to illustrate some basic statistical concepts and techniques.
df.to_csv("monthly-indicators.csv", index=False)