When preparing features (x values) for training machine learning models, it’s essential to convert the data into a numeric format. This is because most machine learning algorithms perform mathematical operations on the data, which require numerical inputs.
So if we have categorical or textual data, we need to use a data encoding strategy to represent the data in a different way, transforming the values into numbers.
We’ll choose an encoding strategy based on the nature of the data. For categorical data, we’ll use either ordinal encoding if there’s an inherent order among the categories, or one-hot encoding if no such order exists. For time-series data, we can apply time step encoding to represent the temporal sequence of observations.
For Categorical Data
Ordinal Encoding
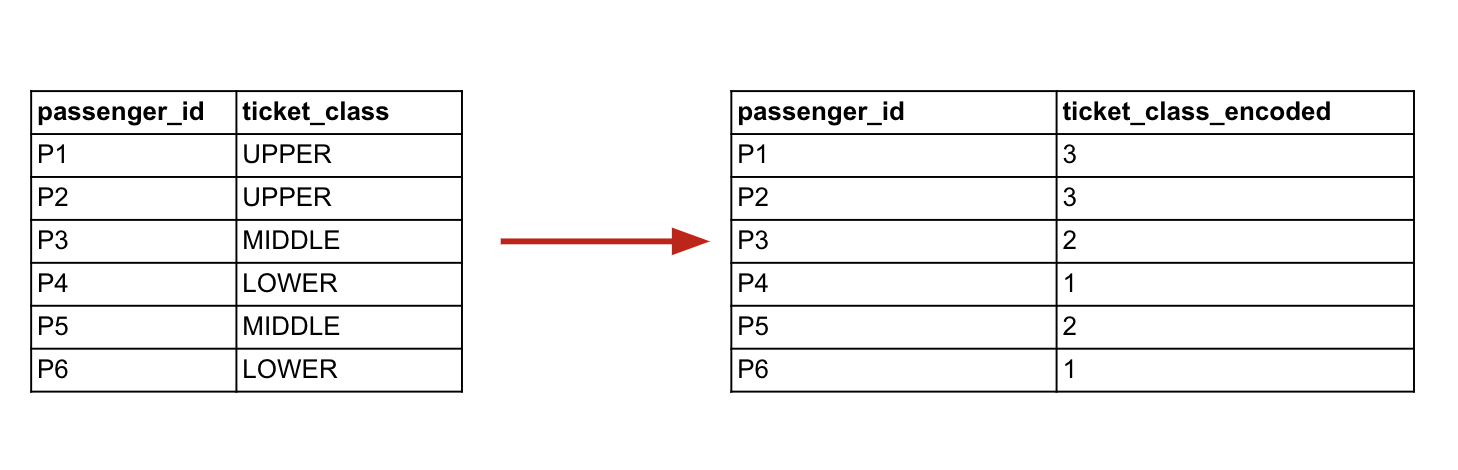
When the data has a natural order (i.e. where one category is “greater” or “less” than another), we use ordinal encoding. This involves converting the categories into a sequence of numbered values. For example, in a dataset containing ticket classes like “business”, “priority”, and “economy”, we can map these to integers (e.g. [1, 2, 3], or [3, 2, 1]), maintaining the ordered relationship.
Example of ordinal encoding (passenger ticket classes).
With ordinal encoding, we start with a column of textual category names, and we wind up with a column of numbers.
To implement ordinal encoding in Python, you can consider a DataFrame mapping operation:
When categorical data has no natural order, we use a technique called one-hot encoding to convert it into a numerical format. In one-hot encoding, each category is represented as a row of binary values, where one element is set to 1 (or True) to indicate the presence of that category, and the remaining elements are set to 0 (or False), indicating the absence of all other categories.
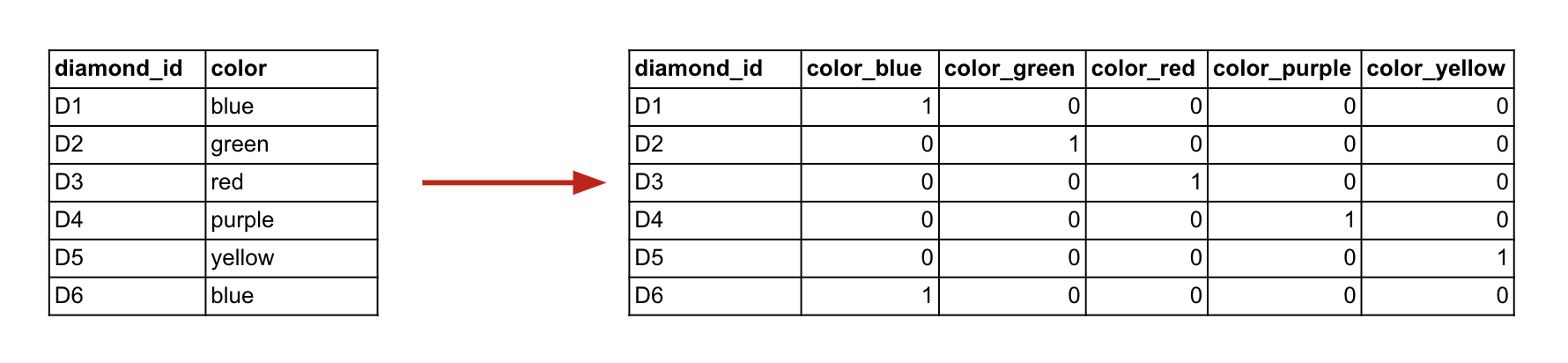
For example, if we have five color categories (blue, green, red, purple, yellow), one-hot encoding transforms the single column of colors into five separate columns. Each column corresponds to one color, and for any given row, a 1 appears in the column that matches the color, while the other columns contain 0s to represent the absence of the other colors.
Example of one-hot encoding for categorical data (diamond colors).
With one-hot encoding, we start with a column of textual category names, and we wind up with as many columns as there were unique values in the original column. This can potentially lead to a large number of features if there are a large number of categories present.
To implement one-hot encoding in Python, we can use the get_dummies function from pandas, specifying a list of columns to encode in this way:
from pandas import get_dummies as one_hot_encode#x_encoded = one_hot_encode(diamonds_df, columns=["color"])x_encoded = one_hot_encode(diamonds_df["color"])x_encoded = x_encoded.astype("int")x_encoded.columns = [f"color_{color}"for color in x_encoded.columns]diamonds_df.merge(x_encoded, left_index=True, right_index=True)
In natural language processing (NLP), we can use one-hot encoding to represent words (or “tokens”) in a sentence. This approach is known as the “bag of words” method. In the bag of words approach, each document is transformed into a row of binary values, where 1 indicates the presence of a given word in that document, and 0 indicates absence of that word. This allows us to turn text into numbers that machine learning models can work with.
Example of one-hot encoding for textual data (i.e. “bag of words” approach).
The bag of words approach is a simple count-based text embedding approach, however more advanced alternative approaches include Term Frequency-Inverse Document Frequency (TF-IDF), and word embeddings. To implement count-based word embedding strategies in Python, we can use the CountVectorizer class, or more commonly the TfidfVectorizer class from sklearn.
For Time-series Data
Time Step Encoding
When working with time-series data, it’s important to encode dates in a way that preserves the temporal structure. A common method is time-step encoding, where each timestamp is assigned a sequential integer value. This approach works well for data collected at regular intervals (e.g. daily, monthly, quarterly, or yearly).
To implement this in Python, we first sort the dataset by date in ascending order, ensuring the earliest date appears first. Then, we create a new column with sequential integers, starting at 1 for the earliest date and incrementing by 1 for each subsequent date:
In summary, different types of data require different encoding strategies. For categorical data, we use ordinal encoding when categories have a natural order, and one-hot encoding when no such order exists. In text data, one-hot encoding is applied through the “bag of words” method to represent the presence or absence of words in documents. For time-series data, time step encoding is used to preserve the temporal order of observations. Choosing the right encoding method ensures that the model can process the data effectively and make accurate predictions.