So far we have covered an example of regression using a single feature variable to predict the target variable.
However in practice, it is common to use multiple features, each of which may contribute to improving the model’s performance.
Considerations
When working with multiple features, there is a trade-off between model performance and model complexity. A model with billions of features, and consequently billions of parameters, can be slower to train and may lead to increased storage and computational costs when deployed. In many cases, a simpler model with fewer features that performs nearly as well can be preferable, especially if it offers faster training, lower deployment costs, and improved interpretability. This trade-off between model complexity and performance should be evaluated based on the specific requirements of the use case, such as the need for speed, scalability, or accuracy.
As previously discussed, one consideration when using multiple features is the potential need to perform data scaling, to standardize the scale of all the features, and ensure features with large values aren’t dominating the model. Although, for linear regression specifically, data scaling is not as important.
Another important factor to keep in mind when using multiple features is the concept of collinearity, which occurs when two or more predictor variables are highly correlated with each other. This can lead to redundancy, where the correlated predictors provide overlapping information about the target variable. Collinearity can cause problems in regression models, such as unstable coefficients, difficulty in interpreting results, and increased sensitivity to small changes in the data. So we should examine the relationships between features before choosing which features to include in the final model.
Data Loading
For an example regression dataset that has multiple features, let’s consider this dataset of california housing prices, from the sklearn.datasets sub-module:
from sklearn.datasets import fetch_california_housingdataset = fetch_california_housing(as_frame=True)print(type(dataset))print(dataset.keys())
.. _california_housing_dataset:
California Housing dataset
--------------------------
**Data Set Characteristics:**
:Number of Instances: 20640
:Number of Attributes: 8 numeric, predictive attributes and the target
:Attribute Information:
- MedInc median income in block group
- HouseAge median house age in block group
- AveRooms average number of rooms per household
- AveBedrms average number of bedrooms per household
- Population block group population
- AveOccup average number of household members
- Latitude block group latitude
- Longitude block group longitude
:Missing Attribute Values: None
This dataset was obtained from the StatLib repository.
https://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.html
The target variable is the median house value for California districts,
expressed in hundreds of thousands of dollars ($100,000).
This dataset was derived from the 1990 U.S. census, using one row per census
block group. A block group is the smallest geographical unit for which the U.S.
Census Bureau publishes sample data (a block group typically has a population
of 600 to 3,000 people).
A household is a group of people residing within a home. Since the average
number of rooms and bedrooms in this dataset are provided per household, these
columns may take surprisingly large values for block groups with few households
and many empty houses, such as vacation resorts.
It can be downloaded/loaded using the
:func:`sklearn.datasets.fetch_california_housing` function.
.. topic:: References
- Pace, R. Kelley and Ronald Barry, Sparse Spatial Autoregressions,
Statistics and Probability Letters, 33 (1997) 291-297
Data Source
This dataset was derived from the 1990 U.S. census, using one row per census block group. A block group is the smallest geographical unit for which the U.S. Census Bureau publishes sample data (a block group typically has a population of 600 to 3,000 people). A household is a group of people residing within a home.
After reading the dataset description, we see features like latitude, longitude, population, and income describe the census block. Whereas age, rooms, bedrooms, occupants, and value describe the homes in that census block.
Our goal is to use the features to predict a target of home value.
Accessing the data, and renaming and reordering the columns for convenience:
df = dataset.frame# rename columns:df.rename(columns={"MedInc": "income", # median income in block group (in)"HouseAge": "age", # median house age in block group"AveRooms": "rooms", # average number of rooms per household"AveBedrms": "bedrooms", # average number of bedrooms per household"Population": "population", # block group population"AveOccup": "occupants", # average number of household members"Latitude": "latitude", # block group latitude"Longitude": "longitude", # block group longitude"MedHouseVal": "value"# median house value (in $100K)}, inplace=True)# reorder columns :df = df[["latitude", "longitude", "population", "income", "age", "rooms", "bedrooms", "occupants", "value"]]df.head()
latitude
longitude
population
income
age
rooms
bedrooms
occupants
value
0
37.88
-122.23
322.0
8.3252
41.0
6.984127
1.023810
2.555556
4.526
1
37.86
-122.22
2401.0
8.3014
21.0
6.238137
0.971880
2.109842
3.585
2
37.85
-122.24
496.0
7.2574
52.0
8.288136
1.073446
2.802260
3.521
3
37.85
-122.25
558.0
5.6431
52.0
5.817352
1.073059
2.547945
3.413
4
37.85
-122.25
565.0
3.8462
52.0
6.281853
1.081081
2.181467
3.422
Data Exploration
Distributions
Examining the distribution of the target variable:
import plotly.express as pxpx.violin(df, x="value", #points="all", box=True, height=350, title="Distribution of Housing Prices", labels = {"value": "Median Housing Price"})
Zoom and pan the map to find the areas with the most expensive homes.
We see the most expensive homes are on the coast. So we can consider using latitude and longitude as features in our model.
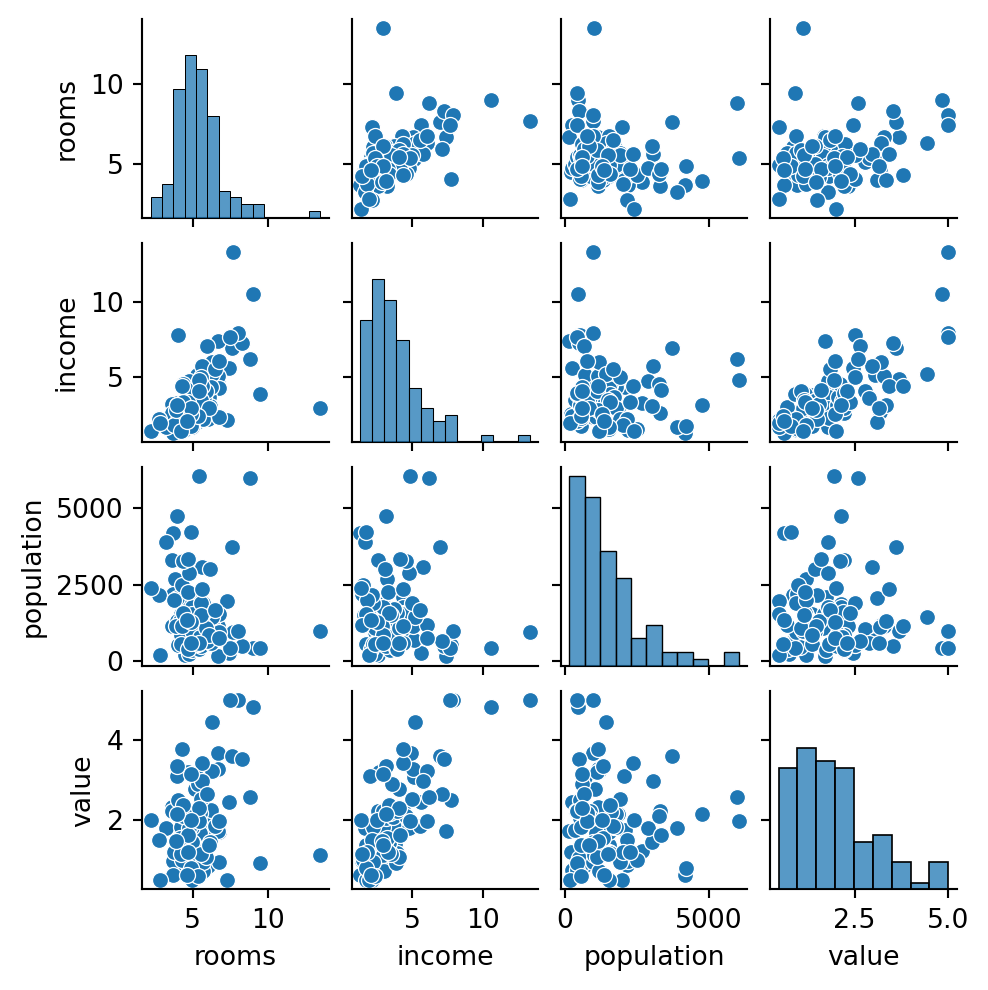
Pair Plots
One way to visualize the relationships between each combination of variables is using the pairplots function from seaborn, however in practice this can take a long time to finish.
from seaborn import pairplot# using all the data (might take a long time):#pairplot(df, hue="value")# taking sample of rows and less columns helps the plot complete faster:df_sample = df.sample(100, random_state=99)pairplot(df_sample[["rooms","income", "population", "value"]], height=1.3)
Correlation
Let’s examine the correlation between the target and each of the features, as well as between each pair of features:
It looks like there is the highest correlation between the target (median home value) and the median income. So we will probably want to keep income as a feature in our model.
There is also high correlation between rooms and income, which makes sense if there are larger houses in areas of higher income. Because these features are highly correlated with each other, we can consider only using one of them in our model, to address collinearity concerns.
X/Y Split
x = df.drop(columns=["value"])y = df["value"]print("X:", x.shape)print("Y:", y.shape)
Training a linear regression model on the training data:
from sklearn.linear_model import LinearRegressionmodel = LinearRegression()model.fit(x_train, y_train)
LinearRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
Examining the coefficients:
from pandas import Seriescoefs = Series(model.coef_, index=x.columns)coefs.name ="Housing Regression Model Coefficients"coefs.sort_values(ascending=False)
income 0.819154
bedrooms 0.276513
age 0.123777
population -0.001711
occupants -0.035253
rooms -0.240811
longitude -0.878116
latitude -0.908597
Name: Housing Regression Model Coefficients, dtype: float64
We see the coefficients with the highest magnitude are income (positive 0.8), and latitude and longitude (each around negative 0.9). These features are contributing the most in explaining the target.
Training metrics:
Code
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_errordef regression_report(y_true, y_pred):"""Displays regression metrics given predicted and actual values.""" r2 = r2_score(y_true, y_pred) mae = mean_absolute_error(y_true, y_pred) mse = mean_squared_error(y_true, y_pred)print("R2:", round(r2, 3))print("MAE:", mae.round(3))print("MSE:", mse.round(3))print("RMSE:", (mse **0.5).round(3))
TRAINING METRICS:
R2: 0.604
MAE: 0.538
MSE: 0.533
RMSE: 0.73
Model Evaluation
Test metrics:
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_errory_pred = model.predict(x_test)print("TEST METRICS:")regression_report(y_test, y_pred)
TEST METRICS:
R2: 0.613
MAE: 0.519
MSE: 0.499
RMSE: 0.706
We see an r-squared score of around 0.61 for the baseline model using all features.
Feature Selection
OK, so we’ve trained a model using all available features, and examined the coefficients to see which features are most predictive. But do we need all the features? Let’s consider which features will give us the most “bang for our buck”, as we explore trade-offs between model performance and model complexity.
To perform this experiment without proliferating lots of duplicate code, here we are abstracting all the logic into a custom function called train_eval, which will accept a list of features as a parameter input. This will allow us to test different combinations of features.
Code
from pandas import DataFramefrom sklearn.linear_model import LinearRegressionfrom pandas import Seriesfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import r2_score, mean_absolute_error, mean_squared_errordef train_eval(df:DataFrame, target="value", features=None, scale=True):"""Trains a linear regression model on a dataset for a given target variable and list of features. Uses all features in the dataframe by default. """# X/Y SPLITif features: x = df[features]else: x = df.drop(columns=[target]) y = df[target]print("FEATURES:", x.columns.tolist())# SCALINGif scale: x = (x - x.mean()) / x.std()# TRAIN/TEST SPLITT x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=99)# MODEL TRAINING model = LinearRegression() model.fit(x_train, y_train)print("--------")print("COEFS:") coefs = Series(model.coef_, index=x.columns)print(coefs.sort_values(ascending=False))print("--------") y_pred_train = model.predict(x_train) r2_train = r2_score(y_train, y_pred_train)print("R2 (TRAIN):", round(r2_train, 3))# EVALUATIONprint("--------") y_pred = model.predict(x_test) r2 = r2_score(y_test, y_pred)print("R2 (TEST):", round(r2, 3))
As we saw earlier, our baseline model (using all the features) gets us an r-squared of around 60%.
train_eval(df)
FEATURES: ['latitude', 'longitude', 'population', 'income', 'age', 'rooms', 'bedrooms', 'occupants']
--------
COEFS:
income 0.819154
bedrooms 0.276513
age 0.123777
population -0.001711
occupants -0.035253
rooms -0.240811
longitude -0.878116
latitude -0.908597
dtype: float64
--------
R2 (TRAIN): 0.604
--------
R2 (TEST): 0.613
We can start by using a single feature, and build from there.
We saw earlier how income is most highly correlated with the target, and its coefficient was high in magnitude. This would be a great feature to start with.
We saw earlier a linear relationship between income and bedrooms, so it’s no surprise adding bedrooms to the model does not provide much “lift” (i.e. help improve performance):
Just these three features give us more or less the same amount of predictive ability as using all the features. So if we take into account model complexity, we might choose these three as the final set of features.