Machine Learning Foundations
Machine learning is a subfield of artificial intelligence that enables systems to automatically learn and improve from experience, without being explicitly programmed. It involves the development of algorithms and statistical models to identify patterns, trends, and relationships in a given dataset, and make predictions or decisions based on that data.
In traditional software development, humans explicitly write the rules or instructions for the computer to follow, to arrive at the desired result or output. But machine learning flips the paradigm. In machine learning, the computer infers or “learns” the rules by examining patterns in the data.
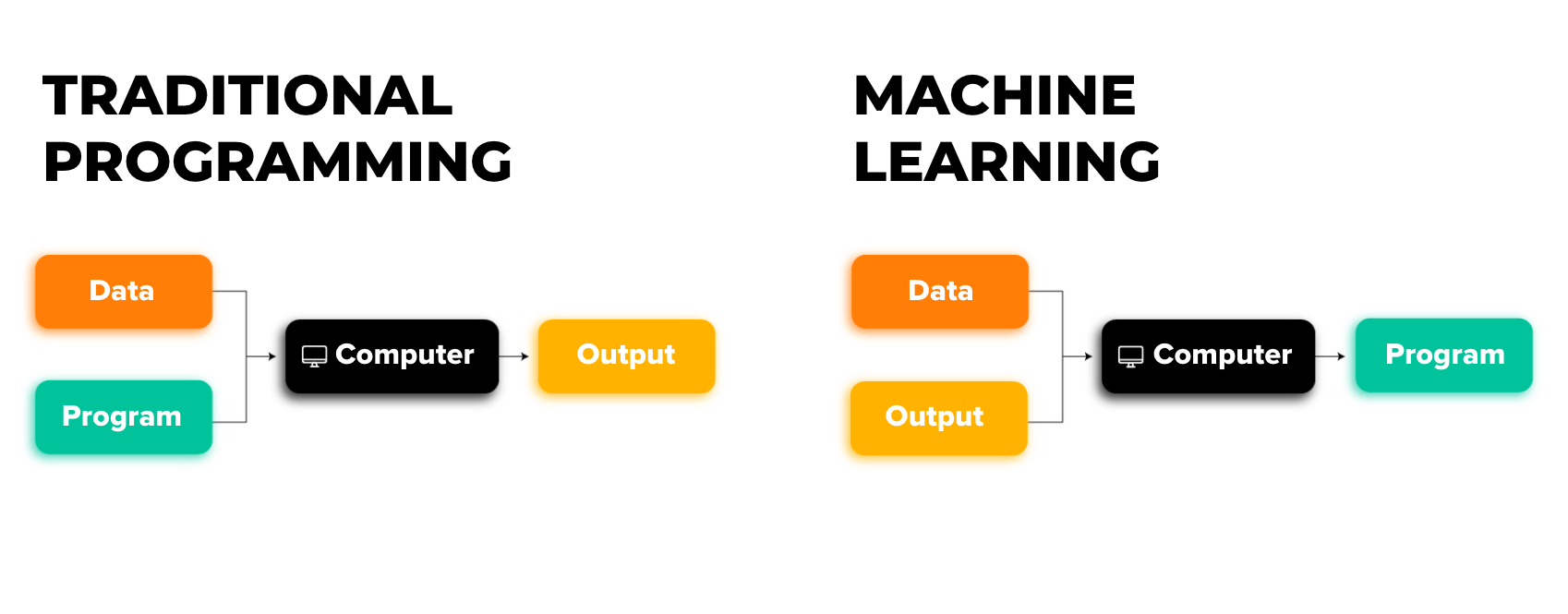
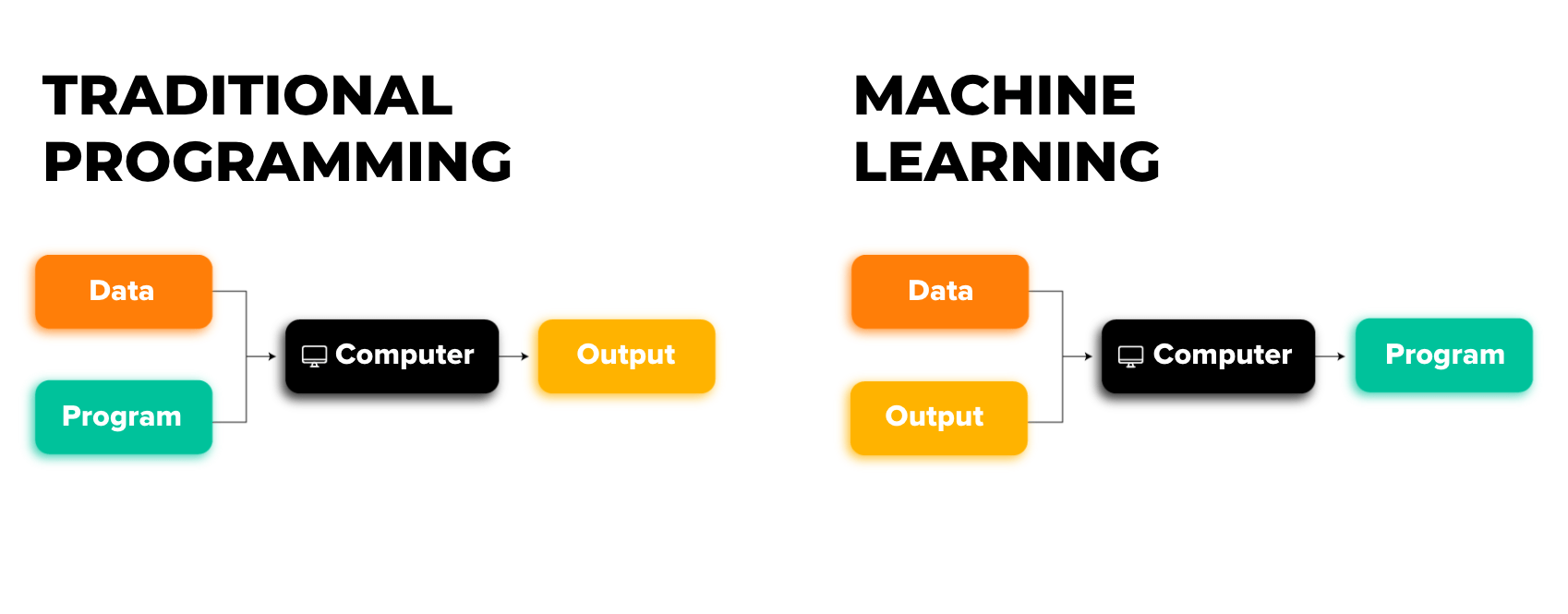{kind=link}
This shift enables machine learning to handle far more complex and nuanced tasks than traditional programming, especially when patterns in the data are subtle or too complicated to capture with simple rules.
Models and Training
A machine learning model is a mathematical representation that captures patterns or relationships in the data. The model’s internal variables, known as parameters (or “coefficients” or “weights”) define the specific patterns or relationships the model has identified in the data.
A machine learning model identifies these patterns through a process called training, where it adjusts its parameters to fit the data. For simpler models, this can involve a closed-form solution, where the optimal parameters are calculated directly. However, more complex models often rely on an iterative optimization process, where the model refines its parameters over multiple rounds to minimize error. While closed-form solutions are faster, they are limited to simpler problems. Iterative methods, such as gradient descent, are more computationally intensive, but allow for modeling more complex, non-linear relationships.
The model is trained on input data known as features, which are the variables or attributes the model uses to make predictions. These features could be anything from numerical values, like a company’s annual revenue, to more abstract representations, such as text embeddings or image pixels.
When available, the corresponding output variable, called the label (or “target”), serves as the outcome the model is trying to predict.

In this example, we see weather-related features such as temperature and humidity levels are being used to predict a target of rainfall.
Types of Machine Learning Approaches
Machine learning can be broadly divided into three categories: supervised learning, unsupervised learning, and reinforcement learning. Each approach has its own set of techniques and applications.
Supervised Learning
In supervised learning, the model is trained on a dataset where both the features and the corresponding labels are known. The system learns to map input features to the correct output labels, allowing it to make predictions or classifications on new data.
Example supervised learning tasks include:
- Regression, where the variable we are trying to predict is continuous (e.g. housing prices); and
- Classification, where the variable we are trying to predict is categorical or discrete (e.g. whether or not an applicant will default on a loan).
Unsupervised Learning
In contrast, unsupervised learning deals with data that lacks labeled outcomes. The model is tasked with finding patterns or groupings in the data without any explicit guidance. While supervised learning focuses on predicting specific outcomes, unsupervised learning seeks to uncover hidden structures or relationships within the data.
Example unsupervised learning tasks include:
- Clustering, where the model tries to arrange similar datapoints into groups; and
- Dimensionality Reduction, where the model reduces the number of features in a dataset while retaining important information.
Reinforcement Learning
Reinforcement learning is a different type of machine learning approach, where an “agent” learns to make decisions by interacting with an environment. The agent takes actions and receives feedback in the form of rewards or penalties, adjusting its strategy to maximize the cumulative reward over time.
Machine Learning Problem Formulation
Machine learning problem formulation refers to the process of clearly defining the task that a machine learning model is meant to solve. This step is crucial in guiding the development of the model and ensuring that the right data, techniques, and metrics are applied to achieve the desired outcome. Problem formulation involves several key components:
Defining the Objective: Identifying the specific problem to solve, such as predicting future stock prices, classifying emails as spam or not, or detecting fraudulent transactions. This is the first step in understanding what the model should accomplish.
Choosing the Type of Problem: Determining whether what type of approach to use (regression, classification, etc.), based on the nature of the target variable and the presence or absence of data labels.
Identifying Features and Labels: Specifying the input variables (features) that the model will use to make predictions and, in the case of supervised learning, the corresponding output or target variable (label) that the model should predict.
Data Availability and Quality: Assessing what data is available, its format, and whether it’s sufficient for training a model. Good data is key, as noisy or incomplete data can lead to poor model performance.
Evaluation Metrics: Establishing how the model’s success will be measured. This could involve metrics like accuracy, precision, recall for classification problems, or r-squared or mean squared error for regression problems.
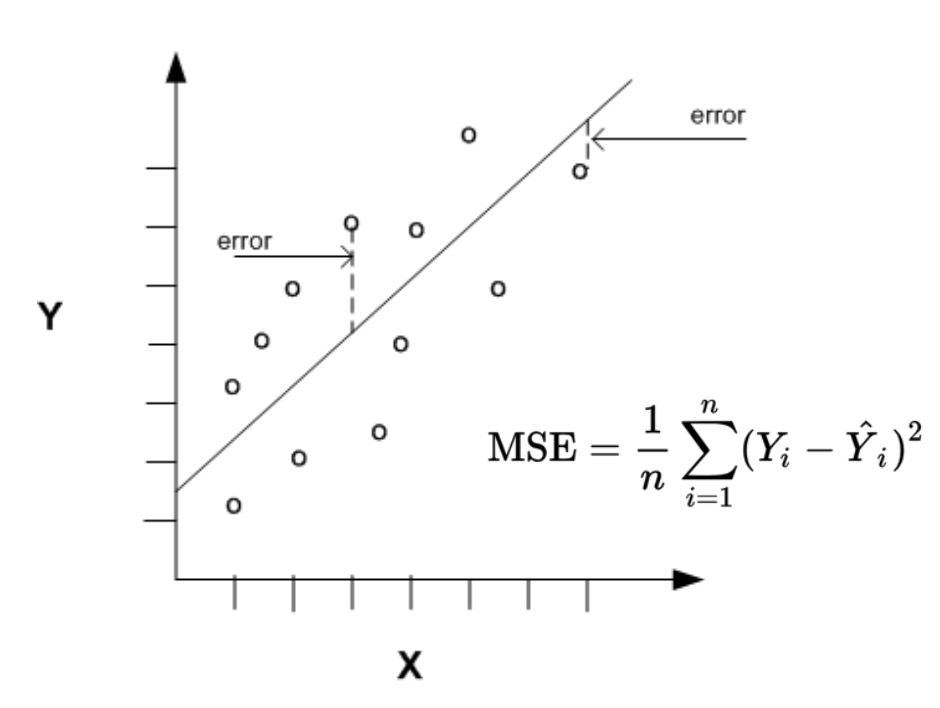
Proper problem formulation ensures that the right machine learning approach is chosen and that the model development process is aligned with the business or research objectives.
Predictive Modeling Process
In practice, the process of predictive modeling can generally be broken down into several steps:
Data Collection and Preparation: Gather historical data and prepare it for analysis. This involves cleaning the data, handling missing values, and transforming and engineering features for better interpretability and accuracy.
Model Selection: Choose the right algorithm for the problem, whether it’s a regression model, a classification model, a time-series forecasting model, etc.
Model Training: Fit the model to the data by using training datasets to find patterns and relationships.
Model Evaluation: Validate the model to ensure it generalizes well to new, unseen data. This typically involves leveraging testing sets or using cross-validation techniques.
Prediction and Forecasting: Once validated, the model can be used to predict outcomes on new, unseen data, providing valuable insights for decision-making.